UE4 性能 - (一)瓶颈定位
stat fps
stat unit
- 其次,之所以需要花精力去“定位”,是由于造成卡顿的原因有多种,而在 UE4 体系中,造成卡顿的因素大致分为三类,隐含在另一个最常用的命令之中:stat unit
![]()
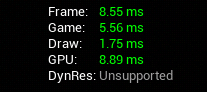
- Frame: 即一帧所耗费的总时间,这个值越大,fps 就越小,二者相乘恒等于 1
- Game: 处理游戏逻辑所耗费的时间
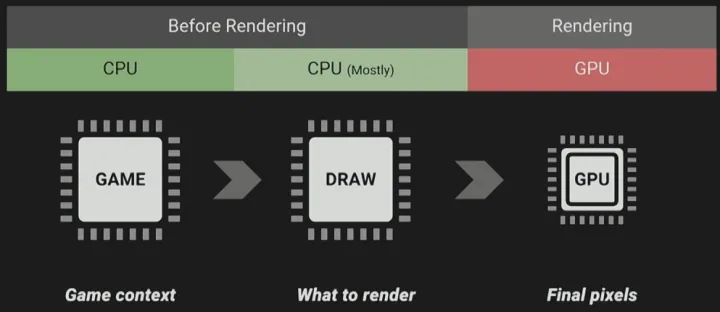
这一步完全不考虑渲染问题,表现的是整个游戏世界在一帧之内,只在逻辑层面处理所有的变化需要花多长时间——Compute Game Context - Draw: 准备好所有必要的渲染所需的信息,并把它从 CPU 发送给 GPU 所耗费的时间
承接上一步,在游戏世界在逻辑层完成所有的计算和模拟后,收集渲染所需的信息,并剔除非必要信息,通知 GPU 进行画面渲染—— What to Render - GPU: 接收到渲染所需信息之后,将像素最终的表现画在屏幕上的耗时
找瓶颈(找内鬼)
瓶颈定位,就是要找到造成性能开销的最大元凶,也就是确定优化的基本方向,才能深入和落实到细节层面,进行后续的分析和优化工作。而要搞清楚开销主要发生在哪个阶段,不可避免地还是要对 Game, Draw, GPU 对应的三类线程以及它们之间的关系有更详细的认识。
Game,Draw,GPU对应的三类线程的关系
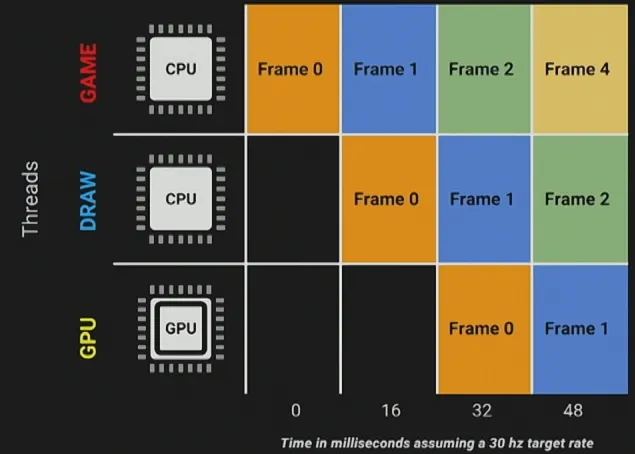
- Game Thread 首先会对整个游戏世界进行逻辑层面的计算与模拟(e.g.Spawn 多少个新的 actor、每个 actor 在这一帧位于何处、角色移动、动画状态等等),所有这些信息会被输送到 Draw Thread
- Draw Thread(也叫 Rendering Thread) 会根据这些信息,剔除(Culling)掉不需要显示的部分(e.g. 处于屏幕外的物体),接着创建一个列表,其中包含了渲染每个物体必备的关键信息(e.g. 如何被着色、映射哪些纹理等等),再将这个列表输送给 GPU Thread
- GPU Thread 在获取了这个列表之后,会计算出每个像素最终需要如何被渲染在屏幕上,形成这一帧的画面
- 综上,对于每一帧来说,这三者的执行顺序依次为:Game Thread → Draw Thread → GPU Thread
- 一帧的总耗时,取决于三者中开销最严重、即耗时最长的线程
- Game Thread 和 Draw Thread 在 CPU 上运行,GPU Thread 在 GPU 上运行
- 如果 GPU Thread 率先完成了它的工作,而其他二者仍在工作中(e.g. 已经绘制好了当前帧,但下一帧的数据还没拿到),那么 GPU 就会等待 CPU 的指令而导致下一帧的画面姗姗来迟;反之如果 GPU 耗时更严重,导致 CPU 输送的数据没有被及时处理,使得画面没能被及时渲染,同样会导致卡顿
优化方向对比
OverView:
- 要定位开销发生在哪个线程,最直接的方法是根据 stat unit 给出的信息,比较 Game, Draw, GPU 三者哪一个与 Frame 的数值最接近(如上述所说,一帧的总耗时取决于三者中的最大值),则它就是造成开销的主要因素
- 利用 UE 内部丰富、强大的各种命令,还可定位出开销具体发生在哪个线程的哪个阶段
- 同时善用 控制变量法,对判断加以验证
Game Thread
- Game Thread 造成的开销,基本可以归因于 C++ 和蓝图的逻辑处理,瓶颈常见于Tick 和代价昂贵的逻辑实现(Expensive Functionality)
- Tick
- 大量物体同时 Tick 会严重影响 Game Thread 的耗时
- stat game:显示 Tick 的耗时情况
- dumpticks:可将所有正在 tick 的 actor 打印到 log 中
- 复杂逻辑
- 需要借助 Unreal Frontend Profiler / Unreal Insights 等工具对游戏逻辑中开销较大的代码进行定位。
Draw Thread (Rendering Thread)
- 需要借助 Unreal Frontend Profiler / Unreal Insights 等工具对游戏逻辑中开销较大的代码进行定位。
- Draw Thread 的主要开销来源于 Visibility Culling 和 Draw Call
- Visibility Culling
- Visibility Culling 会基于深度缓存(Depth Buffer) 信息,剔除位于相机的视锥体(Frustum)之外的物体和被遮挡住(Occluded)的物体,当游戏世界中可见的物体过多,剔除所需的计算量也将变大,导致耗时过长
- stat initviews:显示 Visibility Culling 的耗时情况,同时还能显示当前场景中可见的 Static Mesh 的数量(Visible Static Mesh Elements)
Draw Call
- 一般理解:CPU 准备好一系列渲染所需的信息,通知 GPU 进行一次渲染的过程
- 想象 CPU 指挥 GPU 拿起一支笔刷,蘸好颜料,给某个(或者某一些)多边形(polygon)涂上颜色,来自 CPU 的这条指令就是一次 Draw Call
- 很多情况下,不同的多边形(可能属于不同的 mesh)需要的是同一种颜色(材质),那么在给笔刷蘸好颜色之后,可以一次性给这些多边形上色,而不需要做无谓的重复操作,这个过程就叫做 合批(batching)
- UE 官方解释:a group of polygons sharing the same material (一组使用相同材质的多边形)
- 这个解释虽然准确,但乍一看非常抽象。首先举例来理解:场景中有 100 个多边形(polygon),其中 10 个共同使用材质 A,10个共同使用材质 B,剩余 80 个共同使用材质 C,100 个多边形被分成了 3 组,于是 Draw Call 就等于 3
- 结合之前的一般理解,也可以理解为:CPU 命令 GPU 将笔刷蘸上某一材质对应的颜料,然后一次性给若干个 polygon 上色,这条 CPU 下达的指令就是一次 Draw Call,而这些 polygon 就是 one group of polygons sharing the same material,有多少组这样的 polygon,就等于发生了多少次 Draw Call
- stat SceneRendering 可查看 Mesh Draw Call 的数量
- 即便场景中模型面数多,只要合批机制完善,Draw Call 的数量也可以非常少
- 相比于面数,Draw Call 对性能开销的影响要大得多
GPU Thread
- 顶点处理(Vertex-bound) 导致的瓶颈
- Dynamic Shadow
- 目前动态阴影(Dynamic Shadow)的生成主要依赖 Shadow Mapping,一种在光栅化阶段计算阴影的技术,Shadow Mapping 每生成一次阴影需要进行两次光栅化,因此当顶点数过多(可能源于多边形数量巨大,也可能源于不适当的曲面细分) 时,Dynamic Shadow 将成为 GPU 在光栅化阶段的一大性能瓶颈
- ShowFlag.DynamicShadows 0: 使用该指令可关闭场景内的动态阴影(0表示关闭,1表示开启),可在开启和关闭两种状态间反复切换,查看卡顿情况是否发生明显变化,以此判断 Dynamic Shadow 是否确实造成了巨大开销
- Dynamic Shadow
- 着色(Pixel-bound) 导致的瓶颈
- 运行指令 r.ScreenPercentage 50,表示将渲染的像素数量减半(也可替换成其他 0-100 之间的数),观察卡顿现象是否明显减缓,以此判断瓶颈是否 Pixel-bound
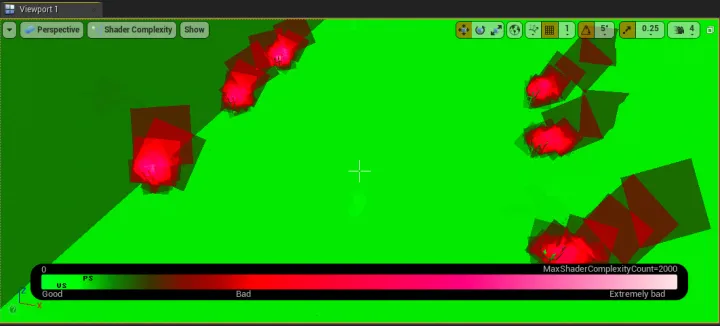
- Shader Complexity
- 显示对每一个像素所执行的着色指令数量,数量越多,消耗越大
- 场景中存在过多的半透明物体(Translucent Object),会显著增加 Pixel Shader 的计算压力,使用 stat SceneRendering 可查看 Translucency 的消耗情况;使用 ShowFlag.Translucency 0 来关闭(0表示关闭,1表示开启)所有半透明效果
- 当着色器(材质连线)的实现逻辑过于复杂或低效时,也会导致较高的 Shader Complexity
- 在 Viewport 中选择 Optimization Viewmodes → Shader Complexity,可视化 Shader 造成的开销
![]()
- Quad Overdraw
- 着色期间 GPU 的大部分操作不是基于单个像素,而是一块一块地绘制,这个块就叫 Quad,是由 4 个像素 (2 × 2) 组成的像素块
- 当模型存在较多狭长、细小的三角形时,有效面积较小,但可能占用了很多 Quad,Quad 被多次重复绘制,会导致大量像素参与到无意义的计算中,引起不必要的性能开销
![]()
进入 Optimization Viewmodes → Quad Overdraw,显示 GPU 对每个 Quad 的绘制次数‘
![]()
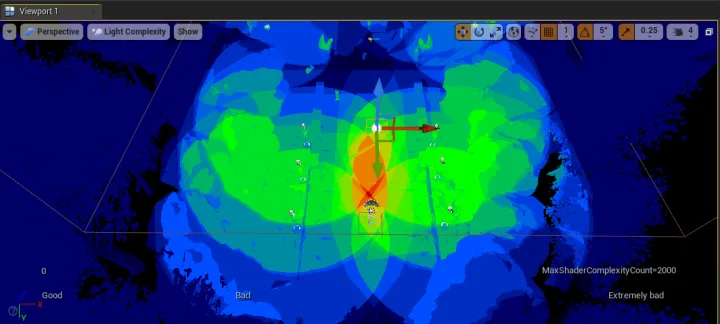
- Light Complexity
- 场景内的动态光源(Dynamic Lights) 数量过多时,会产生大量动态阴影(Dynamic Shadow),如上述所说,容易引起较大开销
- 动态光源的半径过大,导致多个光源的范围出现大量交叠,也可能导致严重的 Overdraw 问题
- 进入 Optimization Viewmodes → Light Complexity,查看灯光引起的性能开销
![]()
- 内存(Memory-bound)引起的瓶颈
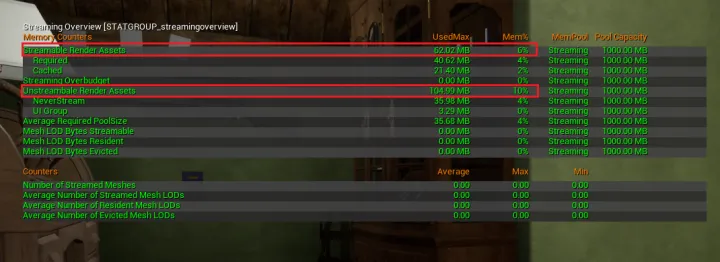
- 有时性能瓶颈还在于过高的内存占用,其中最常见的是大量的纹理(Texture)加载和采样
- 使用 stat streaming overview,查看当前纹理对内存的占用情况
- 对于纹理的优化。
![]()

参考:
Unreal Art Optimization
Profiling and Optimization in UE4 | Unreal Indie Dev Days 2019 | Unreal Engine
UE4 Graphics Profiling: Measuring Performance
UE4 Graphics Profiling: Pipeline and Bottlenecks
Performance Tools in Unreal Engine
Shadow Casting
Performance and Profiling Overview
Ray Tracing Features Settings
Dynamic Scene Shadows
Ray Tracing in UE4
Stat Commands
UE4 性能 - (二) 性能分析工具: Unreal Frontend Profiler
- 常用 性能分析工具 的使用
- Unreal Frontend Profiler
- Unreal Insights
- GPU Visualizer & RenderDoc
- 性能分析操作实例:创建一个复杂度适中的示例工程,基于之前已经介绍过的知识与技能,运用分析工具从各方面分析该工程的性能开销,并确定优化方向
概述:
- Unreal Frontend - Profiler 工具只能检测到 CPU 侧的开销信息,无法用于分析 GPU 方面的性能
- Profiler 工具属于 Unreal Frontend 工具集,可以作为独立应用打开,也可以通过 Editor 打开
- 操作界面较为繁琐,交互体验不如 Unreal Insights
- 可以精确定位到 游戏逻辑 内开销较大的某个方法,并清晰显示其调用和被调用关系
名词解释
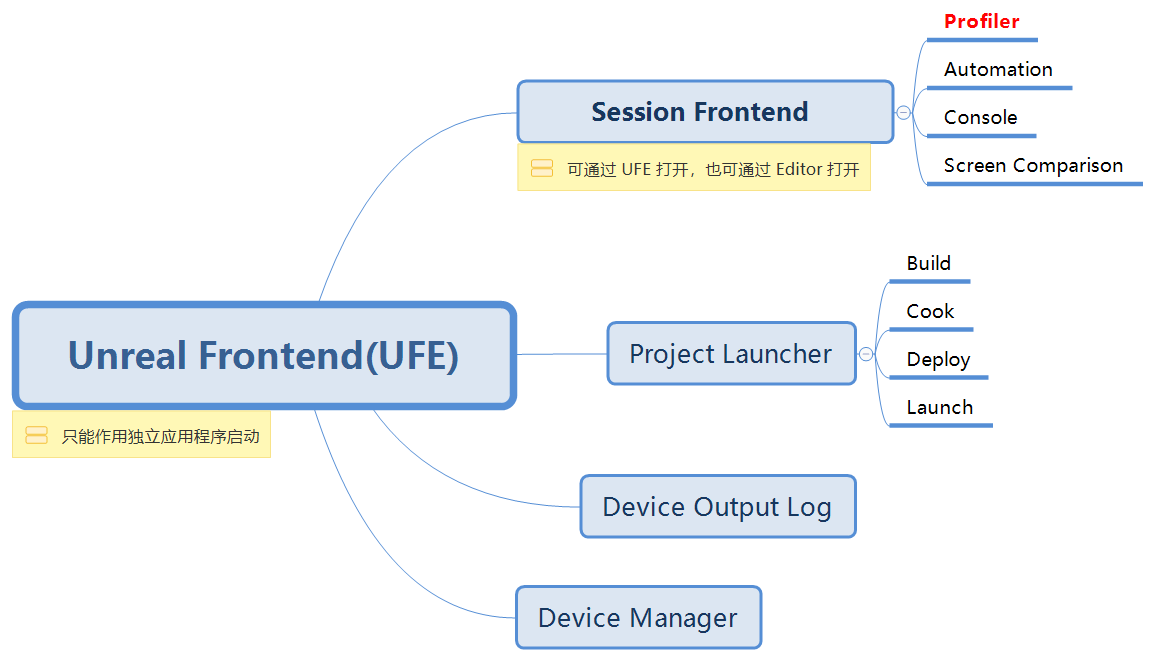
- 当提到 Unreal Frontend 这套工具时,下列称谓时常会伴随出现,就 性能分析 这部分功能来讲,它们似乎说的是同一件事;但作用范围其实存在根本性差异。下面先把这些称谓的具体含义捋清楚,避免混淆误用
- Unreal Frontend: 作用范围最广,包含功能最多;作为独立应用(UnrealFrontend.exe)打开,Session Frontend 是它的子集
- UFE: Unreal Frontend 的简称
- Session Frontend: 属于 Unreal Frontend 的一部分,也 可直接通过 Editor 访问,能够监测到所有运行中的游戏会话(包括 Editor, Standalone 以及连接上 PC 的 Android 会话)
- Profiler: 对性能检测这一具体功能的俗称,属于 Session Frontend 的子集,也是本文真正要讨论的部分
![]()
- Live Data,Captured Data
- Live Data: 指的是贮存在 内存 中的实时数据,只能此刻预览,无法保存以反复查看
- Captured Data: 将实时信息输出成 本地文件 后的数据, 可加载到 Profiler 中反复查看
启动和连接
- 通过上述对 Unreal Frontend 工具集结构的梳理,启动的是 Unreal Frontend 中的 Profiler 工具
- 工程内部(Editor)启动 Window -> Developer Tools -> Session Frontend -> Profiler
- 应用程序启动
- 打开应用 xxx/Engine/Binaries/Win64/UnrealFrontned.exe
- Note:xxx 表示所使用的引擎的安装 根目录
- 打开应用 xxx/Engine/Binaries/Win64/UnrealFrontned.exe
- 定位页签 Session Frontend -> Profiler
- 会话连接
- Windows
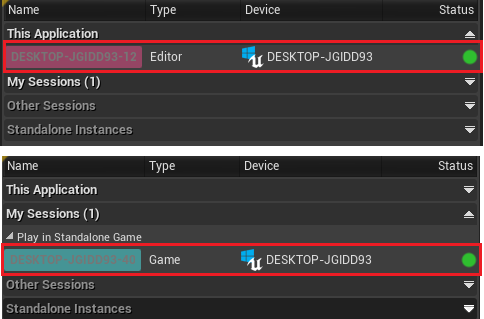
- 无论是通过 Editor 还是 Unreal Frontend.exe 启动,Session 界面都会显示出所有正在运行的游戏会话,包括 Editor 和 Standalone
- 例如我通过 Editor 开启 Profiler 后,又在 Standalone 模式下运行了游戏,那么此时 Session 界面中会出现两个游戏会话
![]()
- Windows
- Android
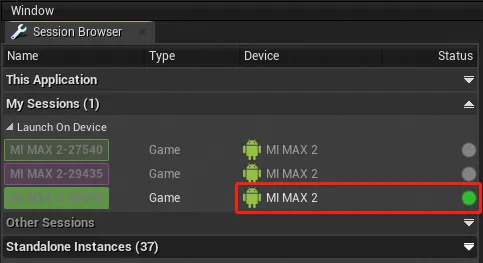
- 将 Android 手机连接至 PC 后打开游戏应用,相应的 Session 也能被工具监测到
![]()
- 将 Android 手机连接至 PC 后打开游戏应用,相应的 Session 也能被工具监测到
界面
整个 Profiler 界面可以分成以下 5 个组成部分:Main Toolbar, Data Graph Full, Filter and Presets 以及 Event Graph,接下来依次说明它们的使用方法
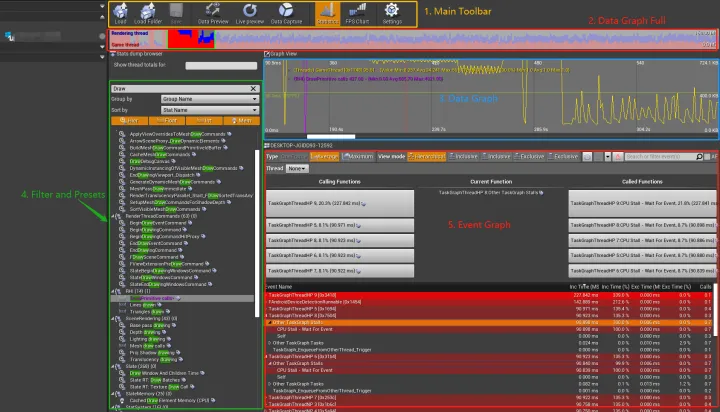
Main Toolbar
顶部的一系列按钮组成了 Main Toolbar 部分,排布着全局的基础操作选项,下面介绍其中最常用的几类操作:
-
Data Preview: 点击后,开始从选中的 Session 抓取实时数据,Data Graph Full 窗口将开始图形化显示线程的耗时情况,此时再次点击即停止抓取
-
Live Preview: 仅在 Data Preview 开启时生效,关闭状态下预览窗口(绿色的滑窗)可以被自由拖拽; 启用后, 该滑窗就将跟随时间轴同步右移(使窗口内显示的是最新的数据)
-
Data Preview 和 Live Preview 两个按钮对应的仅为 预览 功能,抓取到的数据为 Live Data,无法保存, 适用于短平快的观察
-
Data Capture: 第一次点击时相当于执行命令 stat startfile , 会往指定路径生成一个后缀为 .ue4stats 的文件, 随后持续向文件内写入信息, 直至再次点击此按钮, 相当于执行命令 stat stopfile, 停止文件写入
- Note: 默认情况下 .ue4stats 文件将被输出至路径:xxx\Saved\Profiling\UnrealStats(xxx 为工程根目录)
-
Load: 载入指定的 .ue4stats 文件,等效于手动将 .ue4stats 文件拖进界面内
-
Data Capture 和 Load 两个按钮分别是写入和读取 Captured Data,数据保存在本地,可以反复查看
Data Graph Full -
图形化显示性能消耗的整体趋势
-
左上角只显示了 Rendering Thread 和 Game Thread, 从这里也可以看出该工具显示的仅仅是 CPU 侧的开销信息
-
蓝色图像表示 Rendering Thread(Draw Thread) 的开销变化, 红色表示 Game Thread
-
能够预览的数据总量比较有限,超出窗口左侧的数据将被丢弃,即只能预览一定时长范围内的开销数据
-
绿色滑窗(Slide Window)内的数据将被显示到 Data Graph 界面上,滑窗的长度也是固定的
Data Graph Full
-
图形化显示性能消耗的整体趋势
-
左上角只显示了 Rendering Thread 和 Game Thread, 从这里也可以看出该工具显示的仅仅是 CPU 侧的开销信息
-
蓝色图像表示 Rendering Thread(Draw Thread) 的开销变化, 红色表示 Game Thread
-
能够预览的数据总量比较有限,超出窗口左侧的数据将被丢弃,即只能预览一定时长范围内的开销数据
-
绿色滑窗(Slide Window)内的数据将被显示到 Data Graph 界面上,滑窗的长度也是固定的
Data Graph -
图形化显示绿色滑窗范围内性能消耗的具体变化情况
-
顶部 的刻度,表示从点击 Live Preview 开始所经过的 帧数
-
底部 的刻度,表示从点击 Live Preview 开始所经过的 时间
-
从 Filter & Presets 中选择追踪的 stat 数据会实时显示在该界面上
Filter & Presets -
包含从预览开始至今,期间所有的 stat 信息,支持搜索和排序
-
对某一具体 Stat 指标进行双击, 或拖拽进 Data Graph 界面, 可以追踪该指标随时间的变化情况
- 正在被追踪的 Stat 指标, 名字后面会被标记一个星号 *
- 在 Data Graph 界面,将鼠标悬浮在某个指标条目上,点击关闭按钮可以停止对它的追踪
-
如果同一个 Stat Group 内有 Stat 性能正在被追踪,该数量会被显示在 Stat Group 名字后的第二个括号内
-
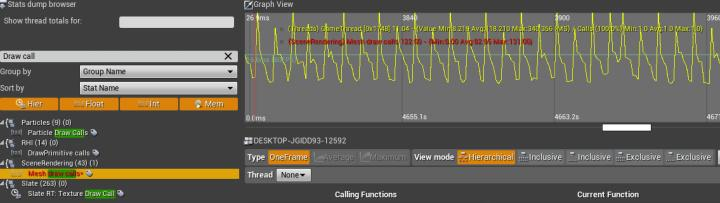
下面实例中,我通过关键字 "Draw Call" 筛选出了相关的 Stats 指标,然后新追踪了名为 DrawPrimitive calls 的指标,最后依次结束了对所有 Stats 的追踪
![]()
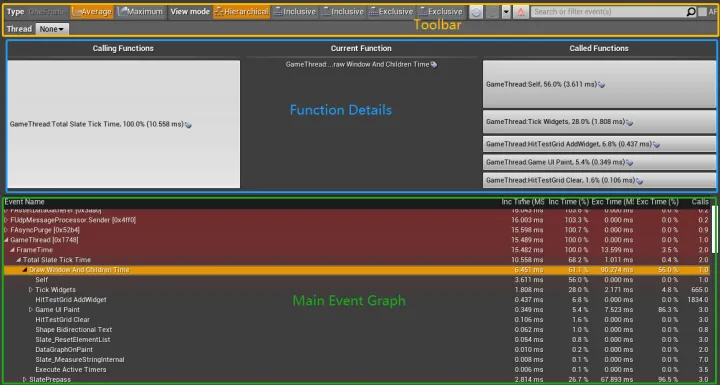
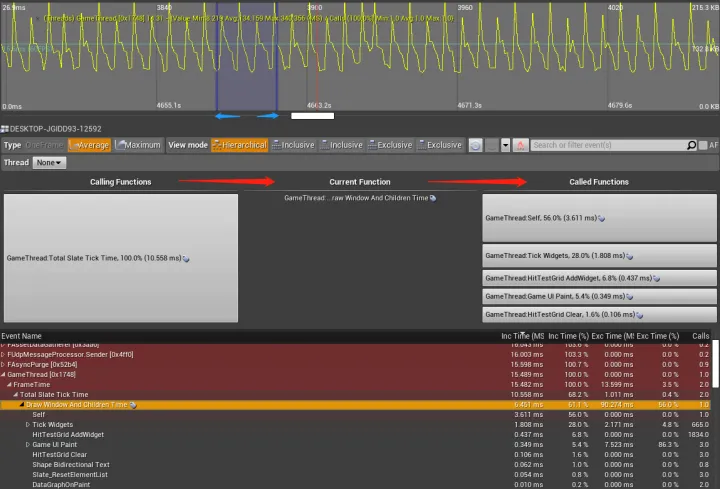
Event Graph
-
显示在 Data Graph 中已选的一帧或多帧期间内, 具体发生了哪些函数调用
-
Main Event Graph
- 底部 区域 称作 Main Event Graph(上图的绿色矩形区域)
- 显示了各 Event / Function 的耗时情况和层级关系
- 在此区域内选中某个方法或事件,Function Details 区域就会显示它详细的调用与被调用情况
-
Toolbar
- 顶部 按钮区域称作 Toolbar(上图的黄色矩形区域)
- Average: 在 Data Graph 中选取了多帧的情况下, 显示它们关于当前 Event 耗时的平均值,默认开启
- Maximum: 在 Data Graph 所选帧当中, 对当前 Event 耗时的最大值
-
Function Details
- 中部 区域称作 Function Details(上图的蓝色矩形区域)
- 表示当前在 Main Event Graph 所选的 Event/Function 的调用与被调用情况
![]()
-
Calling Functions: 显示哪些方法调用了所选的方法, Widget 的尺寸大小表示其调用次数的占比
-
Current Function: 在 Main Event Graph 中被选中的方法
-
Called Functions: 哪些方法被所选的方法调用了, Widget 的尺寸大小表示其被调用次数的占比
-
关于 Calling Functions 和 Called Functions 的调用顺序,可以按上图 红色箭头的指向顺序 来理解
常见操作流程
- 运行游戏,切换到 Profiler 界面
- Main Toolbar 中点击 Data Preview 开始预览性能数据
- 关注 Data Graph Full 内是否出现明显尖峰,如果有并希望马上查看原因,则再次点击 Data Preview 停止预览
- 拖动 Data Graph Full 中的绿色滑窗至尖峰处,开始观察 Data Graph 界面,准确定位导致开销陡升发生在哪一帧或哪一小段
- 在 Data Graph 中选择一段时长范围,此时 Event Graph 将显示这段时长内各方法的耗时情况,按降序排列
- 在 Event Graph 的 Main Event Graph 区域展开条目层级,根据 Function Details 区域显示的信息,一级级深入定位到具体的方法上
参考
UE4 - Profiler Tool Reference
UE4 - UnrealFrontend
UE4 性能 - (三) 性能分析工具:Unreal Insights
Unreal Insights 抓取到的性能数据,依赖一套名为 Trace 的框架,对其中的 Trace Channel 进行配置,能帮助我们专注于分析某些类型的性能开销,屏蔽不必要的信息干扰,同时减少 Profiling 数据所占用的空间。
Trace 是一套日志框架(logging framework),其主要目的是为了便于描述进程中出现的高频事件,并生成一系列的事件流(stream of events)作为性能分析的凭据。
Trace Channels 是 Trace 框架中为了便于用户专注于某一类型的事件流而设计的机制,用户可以只打开自己感兴趣的 channel,从而屏蔽掉不相关的事件流信息。
Trace
Trace 是一套日志框架(logging framework),其主要目的是为了便于描述进程中出现的高频事件,并生成一系列的事件流(stream of events)作为性能分析的凭据 。
Trace Channels 是 Trace 框架中为了便于用户专注于某一类型的事件流而设计的机制,用户可以只打开自己感兴趣的 channel,从而屏蔽掉不相关的事件流信息。
Channels
- 在启动命令行中添加 -trace 参数,指定要开启的 channel,使相应信息能在 Unreal Insights 中被显示
- e.g.-trace=log,frame,cpu,gpu,memory,loadtime,...
- 在 UE 源码中全局搜索关键字 UE_TRACE_CHANNEL_DEFINE,可查看所有支持开启的 trace channel
- 开启 trace channel 之后,推荐添加参数-statnamedevents,显示各个 trace event 的名字和开销情况;其中 event 的名字,就是代码中 TRACE_CPUPROFILER_EVENT_SCOPE(xxx) 括号内的部分,而开销情况所涵盖的范围,就是这个宏的作用域
- 如果不加 -trace 参数,以下 channel 会默认被开启:cpu,frames,log, bookmarks
- 默认开启的 channel 可以在 Engine/Config/BaseEngine.ini 中进行配置
- [Trace.ChannelPresets]
Default=cpu,frame,log,bookmark
- [Trace.ChannelPresets]
- 默认开启的 channel 可以在 Engine/Config/BaseEngine.ini 中进行配置
- 自 4.25 版本起,-cpuprofiletrace, -loadtimetrace, -filetrace 参数已失效
- 使用 trace.pause 暂停对所有 channel 信息的追踪,trace.resume 恢复追踪
